1.什么是栈?
栈:FILO(First In Last Out)的一种数据结构。
详细介绍见维基百科定义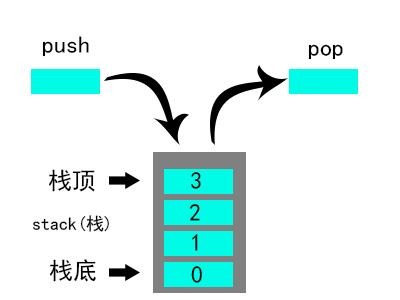
栈拥有的操作
1.push
push操作是将元素扔进栈顶。
2.pop
pop操作将删除并返回栈顶的元素。
3.isEmpty
如果栈里没有元素则返回True,如果有元素则返回False
4.top
如果栈顶有元素,则返回栈顶元素,如果栈顶没有元素,则返回error,或null。
2.方法一:基于list类的栈
基于list实现的栈要依赖Python的内置类list,依靠list本身的操作,加以限制操作的方式实现,这种实现方式最简单。
详细实现
1 | class ArrayStack: |
方法一时间复杂度分析
使用list方法实现的时间复杂度都是常量级别的,时间复杂度上很大程度借了Python实内置函数现方式的光。
| 操作 | 时间复杂度 |
|---|---|
| push | O(1) |
| pop | O(1) |
| top | O(1) |
| isEmpty | O(1) |
| len | O(1) |
3.方法二:单链表实现栈
详细实现
1 | class Stack: |
方法二时间复杂度分析
由于每次入栈出栈,都有一个_size累加累减,所以len的时间复杂度还是1。
| 操作 | 时间复杂度 |
|---|---|
| push | O(1) |
| pop | O(1) |
| top | O(1) |
| isEmpty | O(1) |
| len | O(1) |
4.栈的应用
栈的应用范围还是很广的,比如我们常用的Ctrl + Z(撤销)就是基于栈的,每次返回上一次的操作,还有浏览器,文件管理器等等,总是记录上一次访问也面的地址,收到返回请求的时候直接返回栈顶的地址就行了,多次请求就不断地从栈顶返回就可以了。
括号匹配
1 | def checkValid(valid): |
HTML标签匹配
HTML匹配标签,可以在网页爬虫里用,写浏览器也需要吧。下面这个是简化的,只考虑<></>这种类型的标签对。
find()函数,第一个参数:str 需要查找的字符串,第二个参数:index 起始位置。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def matched_html(html):
stack=Stack()
i=html.find('<') #找到一个标签的‘<’
while i!=-1:
x=html.find('>',i+1)#找到这个标签的‘>’
if x==-1:
#标签错误
return False
tag=html[i+1:x] #获取标签<tag>中的标签名tag
if not tag.startwith('/'): #判断有没有结束标签
stack.push(tag)
else:
if stack.isEmpty():
return False
if tag[1:]!=stack.pop():
return False
i=raw.find('<',x+1)
return stack.isEmpty()
