1. 系统吞吐量
系统吞吐量表示了一个系统的承压能力,受到线程数、进程数、IO、请求对CPU的消耗等影响。单个请求对CPU消耗越高,外部系统接口、IO影响速度越慢,系统吞吐能力越低,反之越高。
1.1 TPS/QPS
QPS(Queries Per Second):每秒能处理的请求个数,针对于单个接口或者服务。
TPS(Transactions Per Second):每秒能处理的事务数,一个事物在分布式系统内可能对应多个请求。针对于整个分布式系统。(如果是单系统,则与QPS相同。
QPS(TPS)= 并发数/平均响应时间
单位:Q/s或T/s
1.2 并发数
某时刻系统能够同时处理的请求数量(QPS/TPS)。
1.3 响应时间(RT)
表示处理一次请求所需的平均时间,包括CPU运算、IO、外部系统响应等时间组成。
2. 分布式与集群
2.1 分布式(distributed)
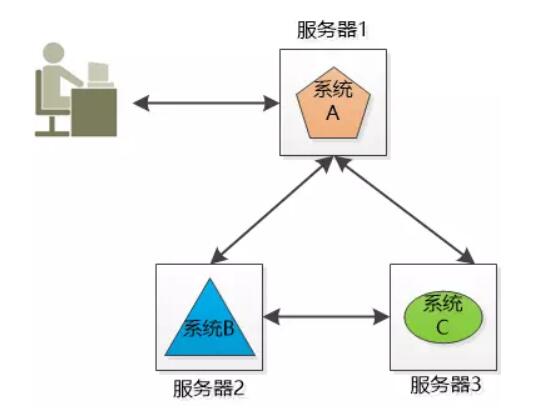
将不同的业务分布在不同的地方, 这就构成了一个分布式的系统,现在问题来了,系统A要分发整个系统,用户量访问大的时候要么是速度巨慢,要么直接挂掉,也就是单点失败。这时候就要用到集群了。
2.2 集群(Cluster)
使用三个A系统,每一份都是系统A的一个实例,对外提供同样的服务,构成了一个系统群,访问数量多了就不会挂掉了。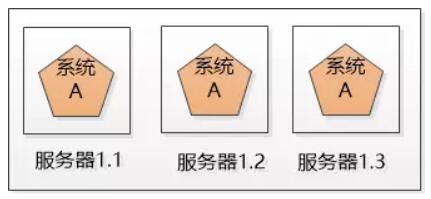
但是每个系统的IP地址都不同,我们应该访问哪一个?如果只访问某一个还是会挂掉。这时候就要用到负载均衡了。
2.3 负载均衡(Load Balancer) 详细内容见标题8
负载均衡,将请求分发到不同的服务器系统上,比如将3万个服务请求均匀分到集群A系统中的各个A系统中。(比如Nginx)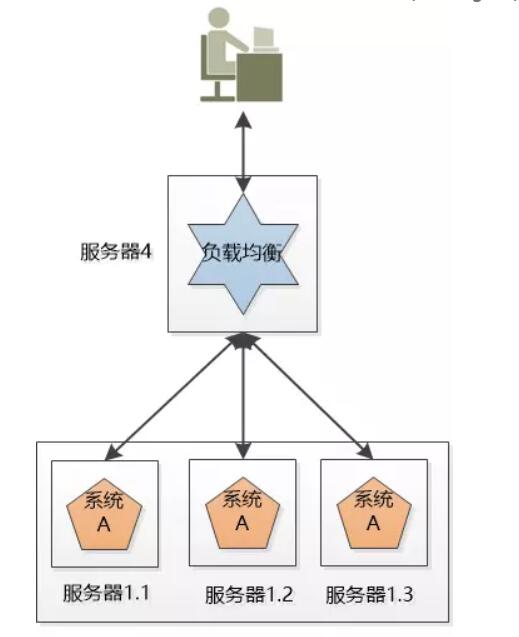
虽然负载均衡只是接收请求、分发请求但是还是可能遇到最初的问题,单点失败。那么我们可以把负载均衡也搞成一个系统集群。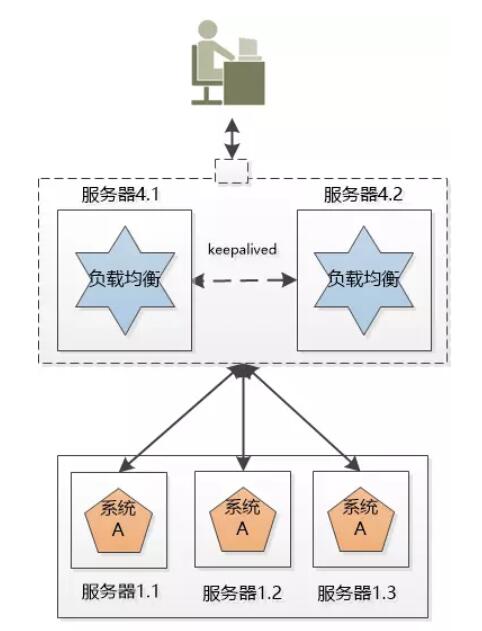
这个新的集群中虽然有两个机器,但我们可以用某种办法,让这个集群对外只提供一个IP地址,也就是说用户看到的好像只有一个机器。
同一时刻,我们只让一个负载均衡的机器工作,另外一个原地待命。如果工作的那个挂掉了,待命的那个就顶上去。
2.4 弹性
如果这3个系统A的实例还是满足不了大量的请求,那就再加服务器!
双11来了,用户量是平时的10倍这时候有两个方案:
① 方案一:购买十几个服务器。
② 方案二:使用云主机(云计算)。
如果使用①,双十一过后,访问数下降,新购的主机就成了摆设,什么卵用都没了,造成了浪费。
如果使用②,在购置的云服务上自由添加删除虚拟机,就不会造成浪费,这就叫弹性。
2.5 失效转移
上面的系统看起来很美好,但是做了一个不切实际的假设:所有的服务都是无状态的。
换句话说,假设用户的两次请求直接是没有关联的。
实际上,大多数请求都是有状态的,比如说:购物车。
如果在服务器1.1上创建一个购物车,并且向其中加入了几个商品,然后1.1挂掉了,被其他服务器接管,那么问题来了,其他服务器上没有1.1里创建的那个购物车,该怎么办?
还有登录,如果把用户的登录保存在1.2的session中,1.2挂了,用户又被跳转到登录界面了,怎么办?
解决方案:
① 把状态信息在集群的各个服务器之间复制,让集群的各个服务器达成一致。(Websphere, Weblogic)
② 把状态信息存在统一的一个服务器里,让各个集群里的服务器都能找到。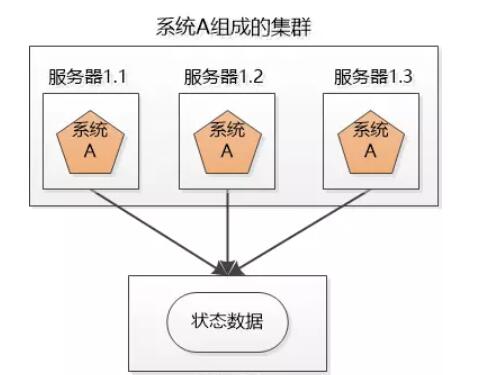
3. 高性能
3.1 高性能的定义
3.1.1 后台系统中的“高性能”主要包括两部分:
- 尽可能多地榨干单台计算机的性能。
- 尽可能高的利用计算机集群的能力。
3.1.2 操作系统和性能最相关的就是进程和线程:
- 每个进程占据独立内存空间,CPU分片串行处理,进程通信,操作系统分配资源的最小单位。
- 线程是进程内部的子任务,共享同一份进程数据,多线程并发,互斥锁,操作系统调度的最小单位。
它们的存在是为了让计算机在 IO 或者网络时,CPU 仍然能忙碌着。具体实现采用多进程还是多线程,不同的业务可能适合不同的方式,没有最好的选择。
Nginx可以用多进程也可以用多线程;JBoss采用的是多线程;Redis采用的是单进程;Memcache 采用的是多线程。
3.2 计算机集群的高性能
拥有计算机集群是提升性能的第一步,第二步就是如何让多台机器配合起来达到高性能。
主要有两种方式:
- 任务分配
- 任务分解
3.2.1 任务分配
指的是在客户端和业务服务器之间增加一层任务分配器,他们的作用就是负责分配任务给合适的机器。这个分配的复杂点在于,任务分配的算法和任务分配器多了,还需要负责分配给任务分配器的分配器。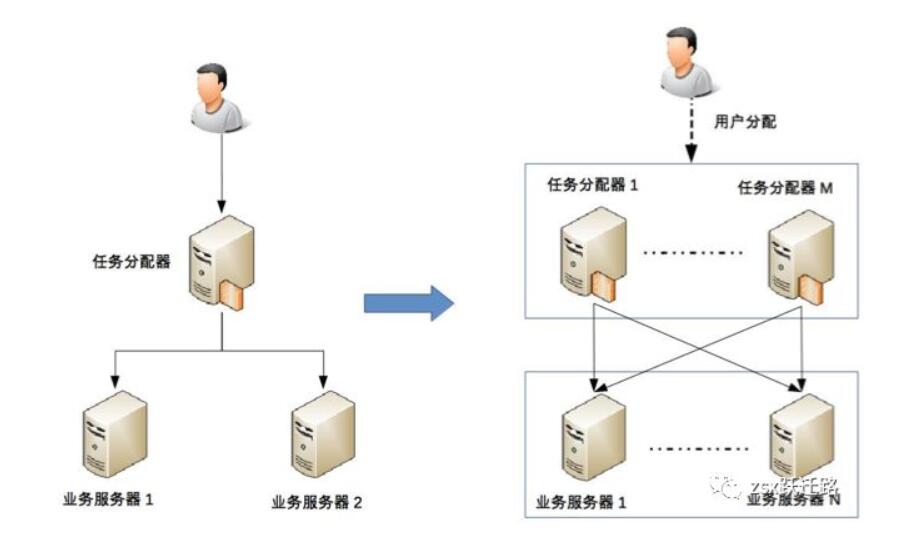
3.2.2 任务分解
指的是将不同的业务系统分配到不同的机器上,把原本大一统但复杂的系统,拆分成多个简单但需要配合的系统,然后再针对部分访问量大的系统做优化。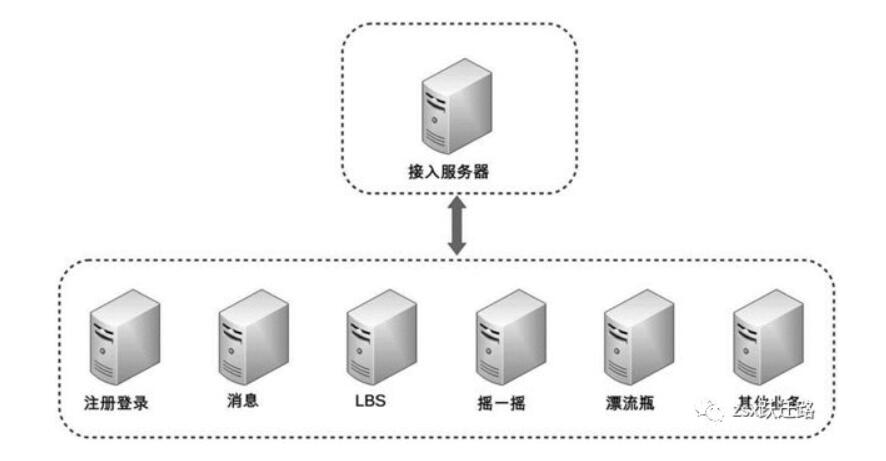
4. 高可用
高可用指的是系统无中断地执行器功能的能力。
难点就在于“无中断”,无论硬件还是软件都会逐渐不可用,比如硬件会逐渐老化,软件会逐渐复杂不好维护。
软件系统的高可用主要是通过增加冗余机器实现的,一般包括两种:
- 计算高可用
- 存储高可用
4.1 计算高可用
“计算”指的是业务逻辑,计算高可用的目的是无论在哪台机器上执行业务逻辑,最后的结果都一致。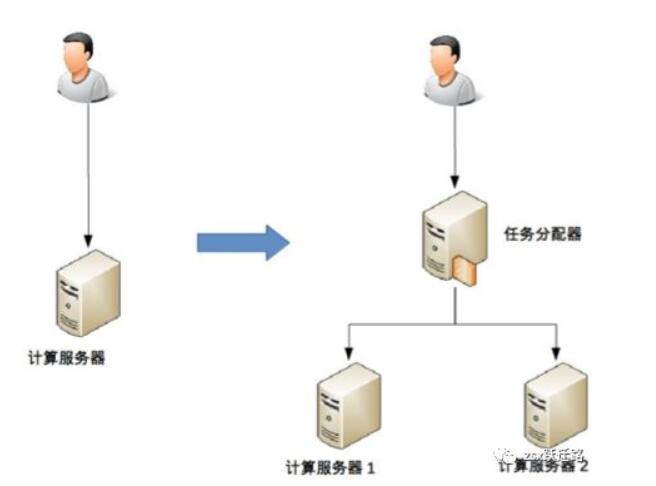
和前面高性能一样,同样需要有一个任务分配器来分配业务给主服务器或备服务器:
4.2 存储高可用
我们知道,数据 + 逻辑 = 业务。存储高可用的目的是尽可能地保证数据在不同机器上都是一致的。
阻碍:由于数据从一台机器搬到另一台机器需要时间,不同地理位置、不同网络状况下需要的时间各不同。对于整个系统而言,在某个时间点上,数据一定是不一致的,最后会导致业务出问题。存储高可用的难点在于如何减少或者规避数据不一致导致的业务异常。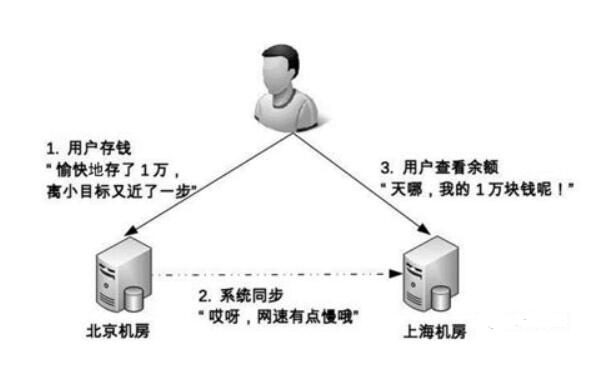
5. 状态决策
无论计算高可用还是存储高可用,本质上都是通过冗余实现。系统需要能够根据当前状态做出决策,一般有三种决策方式:
- 独裁式
- 只有一个独立的决策者,其余冗余的个体不参与决策。优点是简单,缺点是决策者故障时系统就会故障。
- 协商式
- 两台机器通过交流信息,根据规则进行决策,比如主备决策。难点在于规则的确定和信息交换异常的处理。
- 选举式
- 通过投票的方式来进行状态决策。难点在于算法复杂,还有可能乎产生“脑裂”。
6. 可拓展
可扩展性是指系统应对需求变化的一种扩展能力。当新需求出现时,可以不修改或者尽可能少的修改即可支持。
设计可扩展的系统,主要有两步:
正确预测变化
结合行业业务发展方向,预测未来技术方向
结合公司业务发展规模,预测高性能、高可用相关压力
适度预测,不要过度设计
完美封装变化
拆分出变化层和稳定层
设计变化层和稳定层之间的接口
7. 数据库集群
在业务复杂到一定程度后,数据库服务器也需要集群,数据库集群一般有两种实现方式:
- 读写分离
- 分库分表
8. 负载均衡
常见的负载均衡主要有三种:
- DNS 负载均衡
- 硬件负载均衡
- 软件负载均衡
8.1 DNS 负载均衡
8.2 硬件负载均衡
8.3 软件负载均衡
未完待续
未完待续
未完待续
未完待续
未完待续
未完待续
幂等性
防止下订单一大波点击提交
1)利用乐观锁
通过版本号去控制
2)悲观锁也行
select * from xx for update
悲观锁和乐观锁的区别
